지금까지 기초자산과 커버드콜의 성과를 여러 측면에서 비교해 보았습니다. 투자 기간이 길어질수록 커버드콜은 기초자산에 비해 수익률은 낮아지고 위험은 높아지는 자산이었습니다. 장기 투자를 계획하고 있다면 커버드콜은 투자할 가치가 낮은 자산이었습니다.
기초자산과 커버드콜의 이러한 관계가 미래에도 계속 이어질 수 있을까요? 이는 투자자의 중요한 관심사일 수 있습니다. 유지될 거라 예상한다면 기초자산에 투자할 것이고, 그렇지 않다면 좀 더 많은 고민이 필요할 수 있기 때문입니다.
참고: 이 글과 전후 몇 편의 글은 기초자산과 커버드콜을 사례로 파이썬을 활용하여 자산의 성과를 비교 분석하는 방법을 소개합니다. 제 책과 글을 통해 여러 차례 상세하게 설명했지만, 커버드콜은 장기 투자자에게 투자 가치가 없다는 결론이 나오게 됩니다. 커버드콜도 투자자에 따라서는 투자할 가치가 있다고 반론하는 댓글에는 답변하지 않습니다. 대개는 데이터를 어떻게 분석했고, 분석 결과의 의미가 무엇인지 충분히 이해하지 못했기에 나오는 의문이거나, 데이터 분석의 전제를 고려하지 않은 지적이기 때문입니다.

주의: 이 글은 특정 상품 또는 특정 전략에 대한 추천의 의도가 없습니다. 이 글에서 제시하는 수치는 과거에 그랬다는 기록이지, 앞으로도 그럴 거라는 예상이 아닙니다. 분석 대상, 기간, 방법에 따라 전혀 다른 결과가 나올 수 있습니다. 데이터 수집, 가공, 해석 단계에서 의도하지 않은 오류가 있을 수 있습니다. 일부 설명은 편의상 현재형으로 기술하지만, 데이터 분석에 대한 설명은 모두 과거형으로 이해해야 합니다.
관계의 안정성은 무엇으로 판단할 수 있을까?
기초자산과 커버드콜 관계의 안정성은 어떻게 알 수 있을까요? 크게 연역적 접근과 귀납적 접근이 가능합니다.
연역적 접근은 투자 상품의 특징이나 구조에 의해 이렇게 되거나 저렇게 될 가능성이 높다는 결론을 내리는 것입니다. 예를 들어 주식은 장기적으로 예금보다 높은 수익률을 얻을 수 있느냐라는 질문이 있을 수 있습니다. 이에 대한 연역적 설명은 주식은 예금보다 높은 위험을 감수하는 투자이기에, 장기적으로 예금보다 수익률이 높아야 한다입니다.
만일 예금이 장기적으로 주식보다 높은 또는 동일한 수준의 수익률을 얻는다면, 이 세상에 주식회사를 설립해서 상장하는 일은 흔하지 않을 것입니다. 그 투자금을 예금에 두면 더 높은 수익률을 보다 안전하게 얻을 수 있기 때문입니다. 그러니 일반적인 상황이라면 장기적으로 주식이 예금보다 높은 기대 수익률을 가질 거라 예상할 수 있습니다.
동일한 결론을 내기 위해 귀납적으로 살펴볼 수도 있습니다. 지난 100년간 가까이 S&P 500 지수에 투자한 결과가 미국 국채에 투자한 성과보다 높았습니다. 그러니 미국 국채보다 S&P 500 지수를 추종하는 ETF에 투자하는 것이 합리적인 선택일 수 있습니다.
어느 한 가지 방식이 옳거나 더 나은 것은 아닙니다. 상호 보완적입니다. 투자자는 가능하다면 두 가지 방식을 모두 활용해서 판단해야 합니다. 이 연재는 파이썬으로 데이터를 분석하고 표현하는 방법을 소개하기에 귀납적으로 접근해 봅니다. 수학적 모델을 사용하지는 않습니다. 어떻게 데이터를 처리해서 살펴보면, 대략적인 윤곽을 살펴볼 수 있는지를 알아봅니다.
평균-분산 그래프
앞에서 두 자산의 혼합 포트폴리오를 평균-분산 그래프에 표현하는 방법을 소개했습니다. 혼합 포트폴리오는 두 자산의 보완 정도에 따라 다른 형태의 궤적으로 나타납니다. 보완성이 없다면 혼합 포트폴리오는 두 자산을 잇는 선분 위에 위치합니다. 보완성이 조금이라도 있다면, 혼합 포트폴리오는 왼쪽 즉 표준 편차가 낮아지는 방향으로 휘게 됩니다.
다음은 기초자산과 커버드콜로 혼합 포트폴리오를 생성해서 평균-분산 그래프를 그리는 코드입니다.
for p in [1, 5, 21, 63, 126, 252]:
port_df = calc_ports2(df, _period = p, _my_w = [1, 0])
plt.scatter(port_df.Std, port_df.Mean, color = 'tab:blue')
port_df = calc_ports2(df, _period = p, _my_w = [0, 1])
plt.scatter(port_df.Std, port_df.Mean, color = 'tab:orange')
port_df = calc_ports2(df, _period = p, _count = 200)
plt.scatter(port_df.Std, port_df.Mean, s = 1 * p ** (1/2), label = f'{p} days')
plt.gca().xaxis.set_major_formatter(PercentFormatter(xmax = 1, decimals = 0))
plt.gca().yaxis.set_major_formatter(PercentFormatter(xmax = 1, decimals = 0))
plt.legend()
plt.show()calc_ports2() 함수는 [파이썬 분석 11] 장기 투자에 보다 적합한 복리 수익률을 구해보자 (통계량의 주관성)에서 소개하였습니다. 투자 기간에 따라 점차 더 굵은 점으로 포트폴리오 궤적이 나타나도록 설정했습니다.


왼쪽은 위의 코드와 같이 산술 평균 수익률로 그린 그래프이고, 오른쪽은 산술 평균 대신 기하 평균 수익률인 GMean을 써서 나타낸 것입니다. 각 선에서 상단에 있는 오렌지색 점이 기초자산이고, 하단에 있는 파란색 점이 커버드콜입니다. 그 사이를 잇는 선처럼 보이는 점들의 집합이 혼합 포트폴리오입니다.
어느 쪽이든 양상은 동일했습니다. 혼합 포트폴리오는 미세하게 굽어 있기는 하지만, 거의 직선에 가깝게 나타나고 있습니다. 다르게 말하면 기초자산과 커버드콜의 수익률 경향은 투자 기간에 관계없이 거의 동일하기에 혼합하여 얻을 수 있는 추가 이득이 없었다는 뜻입니다
혼합 효과가 없는 자산은 예금 혼합 포트폴리오와 비교하면 우위 관계를 추정할 수 있습니다. 참고: 이 연재는 데이터를 분석하고 그래프로 그리는 기반이 되는 투자 이론은 세세하게 설명하지 않습니다. 이에 대해서는 참고 서적을 읽어 보길 권합니다.
basic_df = calc_ports2(df, _period = p, _my_w = [0, 1])
plt.scatter(basic_df.Std, basic_df.Mean, label = 'Basic')
p7_df = calc_ports2(df, _period = p, _my_w = [1, 0])
plt.scatter(p7_df.Std, p7_df.Mean, label = 'P+7%')
port_df = calc_ports2(df, _period = p, _count = 200)
plt.scatter(port_df.Std, port_df.Mean, s = 0.05, label = f'Basic + P+7%')
plt.scatter(0, 0.02, label = 'Bank')
plt.plot([0, basic_df.Std.mean()], [0.02, basic_df.Mean.mean()],
ls = ':', label = 'Basic + Bank')
plt.gca().xaxis.set_major_formatter(PercentFormatter(xmax = 1, decimals = 0))
plt.gca().yaxis.set_major_formatter(PercentFormatter(xmax = 1, decimals = 0))
plt.xlim(0, 0.16)
plt.ylim(0, 0.14)
plt.legend()
plt.show()예금 이율을 2%로 가정하고 기초자산 + 예금 포트폴리오를 점선으로 나타냈습니다. basic_df.Std에는 하나의 값 밖에 없지만 숫자로 변환하기 위해 mean()을 사용했습니다.
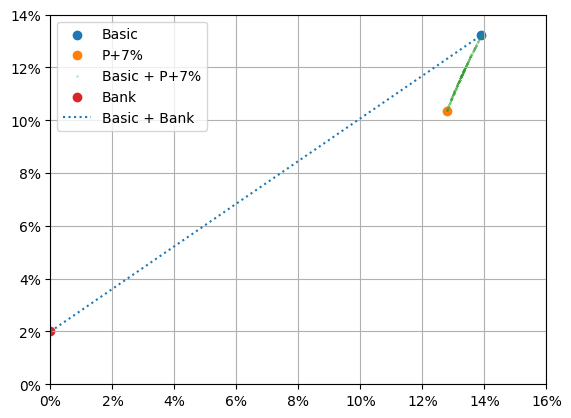
기초자산 + 커버드콜 포트폴리오인 초록색 궤적 왼쪽에 기초자산 + 예금 포트폴리오인 파란색 궤적이 있습니다. 기초자산에 커버드콜을 혼합해서 투자하는 것보다는 예금을 혼합하는 게 평균적으로 더 안전했다는 의미입니다. 평균-분산 분석(Mean-Variance Analysis)에서는 이를 우위에 있다고 말합니다. 참고: 지배 원리(dominance principle)라고 번역된 경우가 많은데, 우위가 더 적절한 번역어라 생각합니다. 평균-분산 그래프에서 dominance 관계는 확률적 우위를 의미하기 때문입니다.
이 그래프만 제대로 이해해도 왜 커버드콜에 장기 투자하면 유리하지 않은지 거의 대부분을 설명할 수 있습니다. 그래프에서 같은 y 값은 동일한 평균 수익률을 의미합니다. 커버드콜에서 왼쪽을 보면 파란색 작은 점이 있습니다. 해당 지점이 커버드콜과 동일한 평균 수익률을 가졌던 기초자산 + 예금 포트폴리오입니다.
그림에서 커버드콜은 대략 (13%, 10%)에 위치하고 있습니다. 대응하는 기초자산 + 예금 포트폴리오는 (10%, 10%) 정도에 위치하고 있습니다. 동일한 1년 평균 수익률 10%에 대해 표준 편차가 13% → 10%로 더 낮은 포트폴리오가 존재했던 것입니다.
투자 비중은 다음과 같이 계산할 수 있습니다. 산술 평균 수익률을 이용한 평균-분산 그래프에서는 평균이 선형성을 띄기에 계산하기 쉽습니다.
(p7_df.Mean - 0.02) / (basic_df.Mean - 0.02)0.744375기초자산에 75% 정도 투자하고, 나머지 25%는 예금에 투자하는 포트폴리오입니다. 이 포트폴리오가 커버드콜과 동일한 수준의 평균 수익률을 가졌던 포트폴리오입니다.
25% 정도가 예금이라면, P+7% 커버드콜의 대략 3년치 분배금에 해당됩니다. 다르게 말하면 이 기초자산 + 예금 포트폴리오는 수익률은 동일하면서 위험은 더 낮았고, 3년치 분배금까지 미리 받아 놓은 포트폴리오가 됩니다.
이러한 이유로 장기 투자자에게는 커버드콜은 적절한 투자 상품이 아닙니다. 위험을 낮추고 싶거나 현금 흐름이 중요하다면, 더 안전하면서 현금을 미리 챙겨 놓을 수 있는 기초자산 + 예금 포트폴리오를 선택할 수 있었기 때문입니다. 기초자산과 커버드콜로 만들어지는 혼합 포트폴리오가 직선 형태에 가깝기에 이 확신의 정도가 크게 높아집니다.
왜 기초자산과 커버드콜에 이러한 관계가 나타나는지는 통계적 분석으로 충분히 설명할 수 없습니다. 이는 연역적 분석으로 살펴보아야 합니다. 통계적 분석은 이러한 관계가 강하게 지속되어 왔기에, 앞으로도 그럴 가능성이 높다고 추정하는 것입니다. 이 때문에 성과 분석에서는 귀납적 방법과 연역적 방법을 함께 활용할 필요가 있습니다.
피어슨 상관 계수
두 자산의 수익률 간에 상관성이 어느 정도였으며, 얼마나 안정적인지 살펴보는 가장 간단한 방법의 하나는 피어슨 상관 계수(Pearson Correlation Coefficient , PCC)의 시간에 따른 변화를 살펴보는 것입니다. 피어슨 상관 계수는 두 자산 수익률의 선형 상관성(linear correlation)을 계산하는 방법의 하나입니다.
이전 글에서 본 기초자산과 커버드콜의 1년 수익률 분포는 다음 그림과 같습니다.

그래프에서 알 수 있듯, 기초자산과 커버드콜의 1년 수익률은 직선에 가깝게 분포하고 있습니다. 피어슨 상관 계수는 모든 점들이 y = ax + b 직선상에 있고, a > 0이면, 1의 값을 가집니다. 전혀 관계없이 분포하면 0이 되고, a < 0인 직선 위에 위치하면, -1이 됩니다.
파이썬에서는 corr() 함수를 이용하여 상관 계수를 구할 수 있습니다. 피어슨 상관 계수가 기본값이며, 이 외에도 켄달(Kendall), 스피어맨(Spearman) 상관 계수를 선택할 수도 있습니다. 필요하다면 사용자가 직접 계산 함수를 만들어서 지정할 수도 있습니다.
1년 수익률의 1년치에 대해 상관 계수를 구하기 위해서는 다음과 같이 사용하면 됩니다.
df.pct_change(US_DAYS).rolling(US_DAYS).corr()
pct_change(US_DAYS)로 1년 수익률을 만들고, 1년치에 대해 1거래일씩 이동시켜 가며 피어슨 상관 계수를 구한 결과입니다. 결과를 보면 1년이 되지 않은 날짜에는 NaN이 들어있습니다. 2개의 자산에 대한 피어슨 상관 계수는 2×2 행렬로 표현됩니다. 값이 정의되지 않은 경우를 제거하고, 2차원 행렬을 1차원으로 만들기 위해 unstack()을 사용합니다.
df.pct_change(US_DAYS).rolling(US_DAYS).corr().dropna().unstack()
각 날짜별로 행이 나타났습니다. 칼럼 부분을 보면 이중으로 되어 있습니다. 멀티인덱스(Multiindex)라고 합니다. 상관 계수는 (A, B)와 (B, A)가 동일하기에 각 행에는 같은 값이 2개씩 있고, (A, A) 또는 (B, B)는 항상 1이기에 1.0이 두 번씩 있습니다.
우리가 관심 있는 결과는 (Basic, P+7%)입니다. 다음과 같이 꺼낼 수 있습니다.
df.pct_change(US_DAYS).rolling(US_DAYS).corr().dropna().unstack()['Basic']['P+7%']
두 자산으로 이루어진 DataFrame에서 상관 계수를 계산해서 시리즈(Series)로 만들어 돌려주는 함수를 정의해 보겠습니다.
def my_corr(_df, _period1 = 252, _period2 = 252):
_corr_df = _df.pct_change(_period1).rolling(_period2).corr().dropna().unstack()
_col1, _col2 = _df.columns
return _corr_df[_col1][_col2]_period1으로 몇 거래일 수익률을 기초 데이터로 사용할 것인지, _period2로 몇 거래일 데이터로 상관 계수를 구할 것인지를 지정할 수 있습니다.
기초자산과 커버드콜의 시간에 따른 상관성 변화
이 함수를 사용해서 기초자산과 커버드콜의 상관 계수 변화를 살펴봅니다.
corr_df = my_corr(df)
corr_df.plot()
plt.ylim(0)
plt.show()
상관 계수가 1에 가까워서 상관성이 높아 보이기는 하지만 어느 정도인지 짐작하기 어려워 보입니다. 다른 자산들은 어떤지 함께 그려봅니다.
corr_df = my_corr(df)
corr_df.plot(lw = 4, label = 'Basic vs P+7%')
plt.xlim(corr_df.index.min(), corr_df.index.max())
for cmp in ['VOO', 'SCHD', 'QQQ']:
corr_df = my_corr(fdr.DataReader(['SPY', cmp]))
corr_df.plot(ls = '--', label = f'SPY vs {cmp}')
plt.ylim(0)
plt.legend()
plt.show()먼저 기초자산과 커버드콜로 상관 계수 그래프를 그렸습니다. 다른 선들과 구분이 용이하도록 굵은 선으로(lw = 4) 지정했습니다. 그래프의 x축 범위는 기초자산과 커버드콜 데이터로 한정했습니다.
SPY에 대해 VOO, SCHD, QQQ의 상관 계수를 동일한 방식으로 계산해서 그렸습니다. 복수 종목에 대한 주가를 가져오기 위해 fdr.DataReader()를 사용할 때 'SPY, VOO'로 사용해도 되지만, ['SPY', 'VOO']와 같이 리스트(list)로 티커 목록을 넘겨줄 수도 있습니다.

상단에 굵은 파란색으로 표시된 선이 기초자산과 커버드콜의 상관 계수입니다. 그 위에 오렌지색 점선은 SPY와 VOO입니다. 두 ETF는 동일한 지수를 추종하기에 항상 거의 1에 가까운 값이 나옵니다.
SCHD는 고배당주 ETF라고 볼 수 있고, QQQ는 성장주 ETF라 볼 수 있습니다. 각각 초록색과 빨간색 점선으로 그려져 있습니다. SPY, SCHD, QQQ는 모두 미국 시장에 상장된 주요 기업에 투자하지만, 시기에 따라 상관 계수의 변화가 꽤 컸습니다. 기초자산과 커버드콜은 이들 조합보다 더 높은 상관성을 가지고 있었으며, 변화폭도 훨씬 작았습니다.
기초자산과 커버드콜은 동일 시장에서 거래되는 특성이 다른 주식형 ETF보다 훨씬 더 비슷했다는 이야기가 됩니다. 이러한 상관성 변화로 유추해 보면, 기초자산과 커버드콜은 수익률 경향이 본질적으로 동일하다고 볼 수 있습니다. 자연히 두 자산 간의 관계도 계속 유지될 가능성이 큽니다.
무슨 말일까요? SPY에 투자하다가, 어떤 이유로 인해 SCHD, QQQ로 변경하는 것은 합리적인 투자가 될 수 있습니다. 상관성 변화가 크기에 일시적으로 수익률 차이가 커질 수 있기 때문입니다.
하지만, 기초자산에 투자하다 커버드콜로 옮기는 것은 그렇지 않을 가능성이 높다는 이야기입니다. 마치 연 0.1% 운용 수수료를 받는 ETF에 투자하다가, 비슷한 지수를 추종하지만 운용 수수료가 2%인 ETF로 바꾸는 것과 크게 다를 바 없다는 의미입니다.
정리하며
기초자산과 커버드콜의 관계가 미래에도 유지될 수 있는지 통계적으로 살펴보는 방법을 소개했습니다. 수학적으로 모델을 세워 분석하는 방식은 아니지만, 실용적인 측면에서 참고할 가치가 있습니다.
투자 분석에서 통계적 접근은 간편하고 유용하기는 하지만, 항상 올바른 결론이 나오는 것은 아닙니다. 주어진 데이터에 한해서, 그리고 특정 조건이 만족된다는 가정하에서, 어떤 결론을 낼 수 있을 뿐이기 때문입니다. 이 때문에 투자자는 데이터가 충분하며, 가정이 합리적인지 확인해야 하고, 필요에 따라서는 연역적 분석을 병행할 필요가 있습니다.
참고: 연재와 관련한 질문은 댓글로 남겨주시기 바랍니다. 답변을 드리거나 이후 연재에서 다룰 수 있도록 노력하겠습니다.
참고 서적: 왜 위험한 주식에 투자하라는 걸까? - 장기 투자와 분산 투자에 대한 통계학적 시각
이어지는 글: [파이썬 분석 20] 인플레이션을 고려해 보자 (한국은행 소비자물가지수 데이터 사용)
연재 목록: 자산 배분 분석 방법 책 소개, 연재글 및 사례 모음 [목록]
함께 읽으면 좋은 글 (최신 글)
- [파이썬 분석 18] 투자 기간에 따른 위험의 변화를 살펴보자 (기초자산과 커버드콜의 경우, VaR, CVaR)
- [파이썬 분석 17] 투자 분석은 왜 통계적으로 접근해야 하나? (기초자산과 커버드콜의 경우)
- [파이썬 분석 16] 두 자산의 수익률 분포를 비교해 보자 (기초자산 수익률에 따른 커버드콜 수익률 분포, +구글 드라이브 이용)
- [파이썬 분석 15] 지수 데이터로 두 자산의 성과를 비교해 보자 (기초자산과 커버드콜 지수 + 외부 파일 읽기)
- [파이썬 분석 14] 두 자산의 성과를 비교해 보자 (TIGER 미국배당다우존스와 TIGER 미국배당다우존스타겟커버드콜2호)
함께 읽으면 좋은 글 (인기 글)
'주식투자' 카테고리의 다른 글
| [파이썬 분석 23] 고정 비율 인출식 성과를 인플레이션을 고려해서 추정해 보자 (+보조 그래프) (0) | 2025.04.26 |
|---|---|
| [파이썬 분석 22] 고정 금액 인출식 성과를 인플레이션을 고려해서 추정해 보자 (1) | 2025.04.25 |
| [파이썬 분석 21] 적립식 성과를 인플레이션을 고려해서 추정해 보자 (0) | 2025.04.24 |
| [파이썬 분석 20] 인플레이션을 고려해 보자 (한국은행 소비자물가지수 데이터 사용) (0) | 2025.04.24 |
| [파이썬 분석 18] 기초자산과 커버드콜 - 투자 기간에 따른 위험의 변화를 살펴보자 (VaR, CVaR) (0) | 2025.04.22 |
| [파이썬 분석 17] 투자 분석은 왜 통계적으로 접근해야 하나? (기초자산과 커버드콜의 경우) (0) | 2025.04.21 |
| [파이썬 분석 16] 기초자산과 커버드콜 (기초자산 수익률에 따른 커버드콜 수익률 분포, +구글 드라이브 이용) (0) | 2025.04.20 |
| [파이썬 분석 15] 기초자산과 커버드콜 (지수 개발사의 기초자산과 커버드콜 지수 + 외부 파일 읽기) (0) | 2025.04.20 |




