두 자산의 가격 데이터를 이용하여 혼합 포트폴리오를 평균-분산 그래프에 나타내 보았습니다. 두 자산을 혼합하면 혼합 비중에 따라 평균-분산 그래프에 곡선 또는 직선의 형태로 포트폴리오가 배치됩니다. 각각의 포트폴리오는 투자자가 선택할 수 있었습니다. 과거 데이터에 대한 요약이기에 예전에 어떤 비중으로 투자했다면, 어떤 결과를 얻었을지에 대한 추정치입니다. 미래에 대한 예측이 아닙니다. 이전 글: [데이터 분석 8] 두 자산의 혼합 포트폴리오를 평균-분산 그래프에 나타내 보자 (구글 시트 편)
과거에 대한 요약이지만, 자산의 특정 경향이 미래에도 어느 정도 지속될 거라는 투자자의 예상이 반영되면, 투자에 참고할 수 있습니다. 제 책이나 이 연재를 포함한 다른 연재에서는 이해의 편의를 위해 과거의 경향이 미래에도 재현된다는 가정하에 설명합니다. 하지만, 미래는 항상 불확실하며, 투자자의 관점이 투영되지 않으면 투자 결정을 할 수 없습니다.
수십 번에 걸쳐 강조합니다만, 통계량은 과거 데이터를 이해하기 쉽도록 요약한 결과일 뿐입니다. 미래에 대한 예측이 아닙니다. 미래에 대한 예측은 투자자가 하는 것입니다. 통계량이 하는 것이 아닙니다.
공지 (2025. 5. 15.) 책 출간으로 인해 부분 공개로 전환합니다. 양해 부탁드립니다. 책 소개: 구글 시트로 시작하는 투자 포트폴리오 분석 (오렌지사과의 불친절한 워크북) 출간에 부쳐 (샘플북 포함)

주의: 이 글은 특정 상품 또는 특정 전략에 대한 추천의 의도가 없습니다. 이 글에서 제시하는 수치는 과거에 그랬다는 기록이지, 앞으로도 그럴 거라는 예상이 아닙니다. 분석 대상, 기간, 방법에 따라 전혀 다른 결과가 나올 수 있습니다. 데이터 수집, 가공, 해석 단계에서 의도하지 않은 오류가 있을 수 있습니다. 일부 설명은 편의상 현재형으로 기술하지만, 데이터 분석에 대한 설명은 모두 과거형으로 이해해야 합니다.
복수 자산의 조합 수와 최적화
(책 출간으로 내용 생략)
| 자산 A | 자산 B |
| 0% | 100% |
| 20% | 80% |
| 40% | 60% |
| 60% | 40% |
| 80% | 20% |
| 100% | 0% |
| 자산 A | 자산 B | 자산 C |
| 0% | 0% | 100% |
| 0% | 20% | 80% |
| 0% | 40% | 60% |
| 0% | 60% | 40% |
| 0% | 80% | 20% |
| 0% | 100% | 0% |
| ... | ||
| 60% | 0% | 40% |
| 60% | 20% | 20% |
| 60% | 40% | 0% |
| 80% | 0% | 20% |
| 80% | 20% | 0% |
| 100% | 0% | 0% |
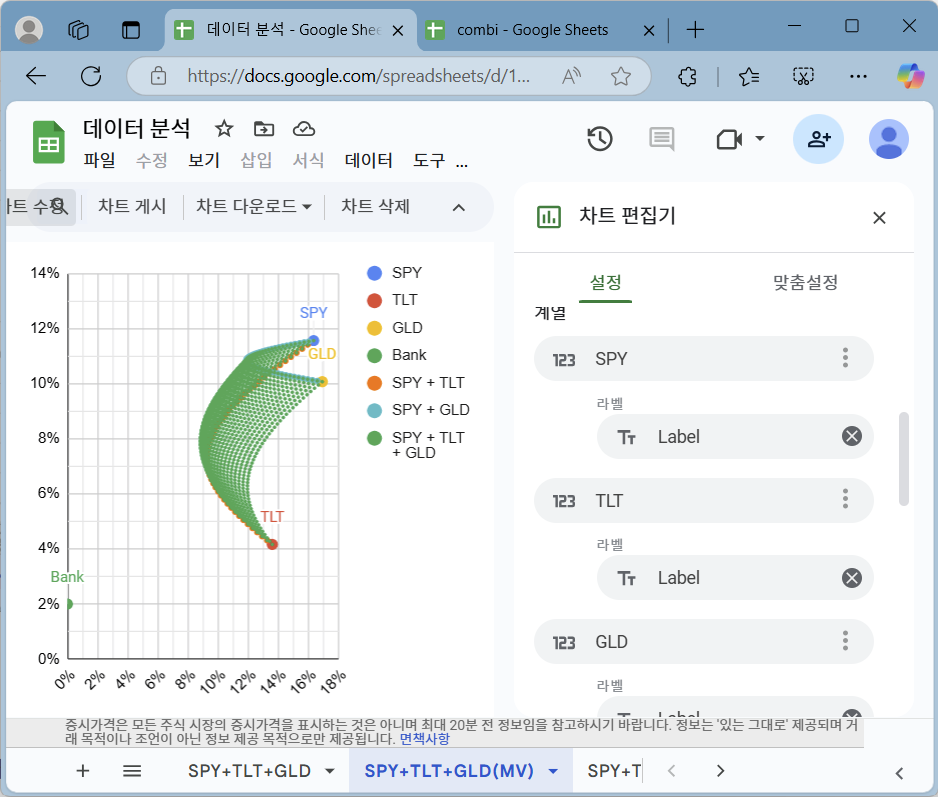
SPY + TLT + GLD 혼합 포트폴리오
(책 출간으로 내용 생략)
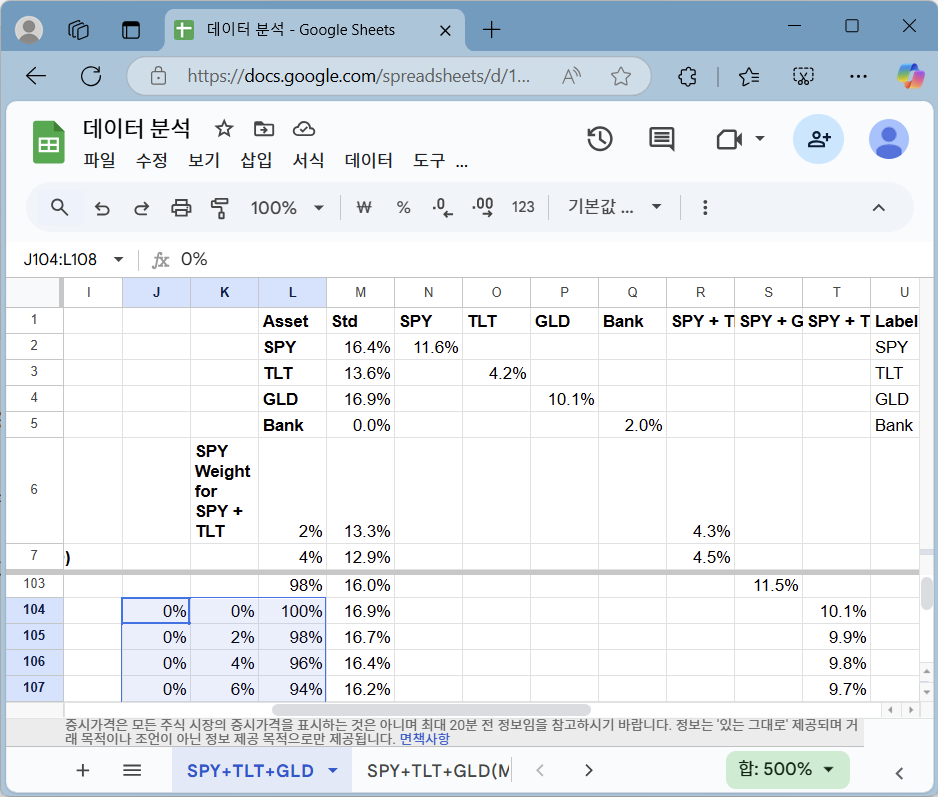


조합 데이터 공유
본 연재의 첫 글에서도 설명했지만, 연재에 사용한 시트를 공유하지 않습니다. 편리함을 익숙해지다 보면, 자칫 본래 목적인 각자에게 적합한 투자 결정을 내리기 위한 데이터 분석에 익숙해지기 어려울 수 있습니다. 사람은 조금 험난한 길이 장기적으로 도움이 될 거라는 것을 머리로는 알더라도, 쉬운 길이 눈에 보이면 그 길을 선택하는 경향이 있기 때문입니다.
이 연재에서 제시하는 예제는 스프레드시트에 익숙한 분에게는 어려운 부분이 거의 없을 것입니다. 스프레드시트에 익숙하지 않은 분이라면, 이번 기회에 스프레드시트 사용법을 배워가며 시행착오와 함께 경험을 쌓는 것이 장기적으로 도움이 될 수 있다고 생각합니다.
이 연재를 읽고 본인이 사용할 시트를 직접 만들고, 다른 분들에게도 도움을 주기 위해 시트를 공유하는 것은 환영하고 권장합니다. 다만 다른 분들이 제공하는 시트를 참고하거나 사용하더라도 기본 과정은 직접 해 보길 권합니다. 투자자마다 투자 목적이 다를 수 있기에, 최종적으로는 본인에게 맞춰 직접 시트를 만들거나 수정해야 할 수 있기 때문입니다.
자산별 투자 비중 조합을 스프레드시트로 자동으로 생성할 수 있을 줄 알았는데, 어떻게 하면 될지 감이 잘 오지 않습니다. 제가 스프레드시트를 잘 다루는 편은 아니기 때문입니다. 하나씩 입력하기에는 개수가 많고 실수도 있을 수도 있기에, 파이썬(Python)으로 생성한 데이터를 공유합니다. (구글 시트 공유 링크)
자산이 2가지 또는 3가지인 경우에는 2%와 5% 단위로 조합되어 있고, 4가지인 경우에는 5% 단위로 조합되어 있습니다.

정리하며
세 개의 자산을 혼합한 포트폴리오를 평균-분산 그래프 상에 나타내 보았습니다. 두 개의 자산 혼합에서 확장해서 동일한 방법을 적용할 수 있습니다. 다만 계산량이 증가할 수 있습니다. 혼합 포트폴리오는 그물의 형태가 되며, 투자자는 각자의 상황에 맞는 포트폴리오 위치를 그래프에서 확인할 수 있습니다.
이어지는 글: [데이터 분석 10] 특정 포트폴리오를 평균-분산 그래프에 표시해 보자 (구글 시트 편)
목록: 자산 배분 분석 방법과 사례 글 모음 [목록] (순서대로 차근차근 읽기를 권합니다)
출간 안내: 연재를 묶어 읽기 쉽게 보완하여 편집한 책이 종이책(교보문고)과 전자책(리디북스, 교보문고, Yes24, 알라딘)으로 출간되었습니다. 책 소개: 구글 시트로 시작하는 투자 포트폴리오 분석 (오렌지사과의 불친절한 워크북) 출간에 부쳐 (샘플북 포함)
참고 서적: <왜 위험한 주식에 투자하라는 걸까? - 장기 투자와 분산 투자에 대한 통계학적 시각> - 이 연재에서 소개하는 각종 분석 방법의 의미를 소개합니다.
함께 읽으면 좋은 글:
- [데이터 분석 8] 두 자산의 혼합 포트폴리오를 평균-분산 그래프에 나타내 보자 (구글 시트 편)
- [데이터 분석 7] 자산과 예금의 혼합 포트폴리오를 평균-분산 그래프에 나타내 보자 (구글 시트 편)
- [데이터 분석 6] 수익률 분포를 정규 분포로 모델링하고 위험을 추정해 보자 (구글 시트 편)
- [데이터 분석 5] 수익률 분포를 정규 분포와 함께 그려보자 (구글 시트 편)
- [데이터 분석 4] 주가 데이터에서 위험 지표인 MDD를 뽑아보자 (구글 시트 편)
- S&P 500 국내 ETF는 무엇이 좋을까? (국내 상장 ETF 9종 비교와 분석)
- 나스닥 100 국내 ETF는 무엇이 좋을까? (국내 상장 ETF 5종 비교와 분석)
- 당신이 커버드콜에 장기 투자하면 안되는 이유 (매년 100만원씩 손해보지 않는 방법) 출간에 부쳐 (샘플북 포함)
- 한국인은 커버드콜 ETF에 장기 투자해도 좋을까? - 커버드콜 ETF에 대한 글 모음
- QQQ5(QQQ 5배 레버리지)는 1년간 얼마나 녹았을까?
'주식투자' 카테고리의 다른 글
| [데이터 분석 13] 두 자산의 상대 수익률 변화를 살펴보자 (구글 시트 편, feat. 미국배당다우존스 커버드콜) (0) | 2025.01.11 |
|---|---|
| [데이터 분석 12] 자산과 환율의 시간의 흐름에 따른 상관성 변화를 살펴보자 (구글 시트 편) (0) | 2025.01.11 |
| [데이터 분석 11] 환율을 반영한 환노출 주가를 계산하고 평균-분산 그래프에서 환헤지와 비교해 보자 (구글 시트 편) (0) | 2025.01.09 |
| [데이터 분석 10] 특정 포트폴리오를 평균-분산 그래프에 강조해서 나타내 보자 (구글 시트 편) (0) | 2025.01.08 |
| [데이터 분석 8] 두 자산의 혼합 포트폴리오를 평균-분산 그래프에 나타내 보자 (구글 시트 편) (0) | 2025.01.07 |
| [데이터 분석 7] 자산과 예금 혼합 포트폴리오를 평균-분산 그래프에 나타내 보자 (구글 시트 편) (0) | 2025.01.07 |
| [데이터 분석 6] 수익률 분포를 정규 분포로 모델링하여 위험을 추정해 보자 (구글 시트 편) (0) | 2025.01.07 |
| [데이터 분석 5] 수익률 분포를 정규 분포와 함께 그려보자 (구글 시트 편) (0) | 2025.01.06 |




